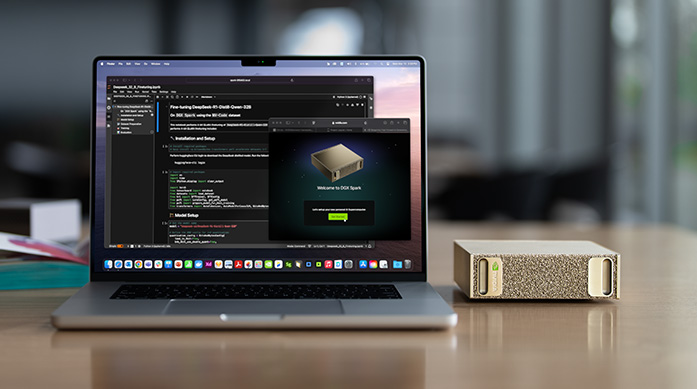
El DGX Spark es el primer ordenador de sobremesa que integra el superchip GB10 Grace Blackwell, comprimido en un chasis de 15 cm. Con 1 000 TOPS FP4 y 128 GB de memoria unificada, promete entrenar, ajustar e inferir modelos generativos y de IA física sin recurrir a un clúster externo. Jensen Huang lo presentó como la piedra angular de una cadena edge‑cloud destinada a robots humanoides, vehículos autónomos y gemelos digitales.
Contexto: la era de la IA física
Hasta ahora la IA se quedaba en la pantalla: modelos generativos que producen texto, imagen o audio. NVIDIA acuñó “Physical AI” para referirse a agentes que perciben, planean y actúan en el mundo real—robots, coches autónomos, maquinaria industrial—cerrando el bucle entre simulación y despliegue.
Pilares de esta visión:
- Modelos fundacionales de mundo (Cosmos) para razonar sobre escenas físicas.
- Motores de simulación diferenciable (Newton, sucesor de MuJoCo/Warp).
- Ordenadores edge capaces de entrenar in‑situ —ahí entra el DGX Spark.

Arquitectura Grace Blackwell al detalle
| Parámetro | GB10 (DGX Spark) | GB200 (Data‑center) | Diferencia clave |
|---|---|---|---|
| Nodo | TSMC 4NP | TSMC 4NP | Igual |
| Transistores | 208 B | 208 B | Ídem |
| Memoria directa | 128 GB LPDDR5X | 192 GB HBM3E | Ancho de banda sacrificado (273 GB/s vs 1 TB/s) |
| Tensor Cores | 5.ª gen + FP4 | 5.ª gen + FP4 | Igual |
| TDP | < 350 W (objetivo) | 1,2 kW módulo | 3–4× menor |

Innovaciones principales:
- FP4 micro‑scaling: dos bits para exponente y dos para mantisa, duplicando densidad frente a FP8 con ~97 % de precisión en LLMs.
- Sparsity 2:4 hardware: ahorro real de 2× energía en inferencia.
- RAS in‑silicon: autodiagnóstico y corrección ECC que cubre hasta 2 bit/word, esencial en cockpits y robots.
- Security enclave: cifrado de memoria completo y arranque verificado en un chip híbrido CPU+GPU.
Diseño industrial y termal del DGX Spark
| Característica | Detalle |
|---|---|
| Dimensiones | 150 × 150 × 50,5 mm |
| Peso | 1,2 kg (sin fuente) |
| Disipación | Cámara de vapor + ventilador radial (40 dB(A) máx) |
| Entradas | 2 × USB‑4 (40 Gb/s), 2 × 10 GbE, SD express 9.1 |
| Expansión | PCIe Gen5 ×8 (eGPU/Networking) |
Enfriamiento “inverted chimney”: el aire entra por la base, atraviesa el heat sink y sale por la tapa ventilada. Permite apilar unidades (“Spark Pair”) usando NVLink‑over‑cable (800 GB/s) para modelos de 400 B parámetros.
Fuente externa GaN: fuente de 48 V/9 A (430 W pico) ubicada fuera del chasis, conectada por un conector tipo MagSafe‑like.
Pila de software: de CUDA‑X a Omniverse
- CUDA 12.5 añade soporte nativo FP4 y una API de “confidence calibration” para frameworks (PyTorch, JAX).
- Isaac Lab 2025.2 compila entornos RL directamente a Warp o JIT‑CPU para pruebas rápidas.
- Omniverse Cloud XR opcional para render‑in‑the‑loop en ADAS y digital twins.
Aplicaciones en robótica
Humanoides generalistas
- Isaac GR00T N1 entrena skills como apertura de puertas o manejo de utensilios. Un Spark puede fine‑tunar 250 k pasos de una política de 1,3 B parámetros en 9 h, consumiendo 3,1 kWh.
- Modo “LLM S” (≤80 W): reduce frecuencia de GPU manteniendo caches activas para prolongar autonomía en humanoides ligeros.
Cobots y brazos industriales
- Programación por demostración con visión multimodal (RGB+depth+fuerza). El Spark ejecuta un ViT‑T de 288 M parámetros con LoRA en tiempo real (93 fps).
- Control real‑time en E‑cores con jitter < 16 ns gracias a Grace Hypervisor, sin PLC externo.
Drones y logística
- Path‑planning neuronal en 25 ms con Graph‑RL; latencia total sensor→actuador < 45 ms para hexacópteros a 12 m/s.
Vehículos autónomos y simulación de tráfico
- Generación sintética con Cosmos a 100 fps de vídeo 4K HDR físicamente coherente para datasets de percepción.
- Integración con DRIVE como edge‑logger: pipeline LiDAR/Cam → UNet2 FP4 → RNN‑Planner en 14 ms; grabación NVMe cifrada a 2 GB/s.
- Huella de carbono más baja: 100 h de entrenamiento en Spark consume 145 kWh vs 370 kWh en un DGX H100.

Comparativa con Apple M4 y AMD MI350
| DGX Spark | Mac Studio (M4 Max) | Workstation MI350A | |
|---|---|---|---|
| P‑TOPS (INT8/FP4) | 1 000 / 520 | 60 (INT8) | 780 (FP8) |
| Memoria | 128 GB LPDDR5X | 192 GB LPDDR5X | 288 GB HBM3E |
| BW efectivo | 273 GB/s | 270 GB/s | 8 TB/s |
| Enfoque | Formación + inferencia local | Inferencia NPU prosumer | Entrenamiento en rack |
| PVP* | < 7 000 USD | 3 999 USD | > 10 000 USD |
*Estimado; NVIDIA no ha confirmado precio.
Impacto en el mercado de hardware especializado
- Democratización de I +D: por < 10 k € se accede a potencia antes reservada a racks de 30 k €.
- Presión sobre AI‑PCs: redefine eficiencia/watt para NPUs y discreta CPU+GPU.
- Cadena de suministros: impulso a LPDDR5X soldado en placa y switches 10/25 GbE SOHO con TSN.
- Software lock‑in: CUDA y Isaac creando barreras de migración; competidores van rezagados.
Disponibilidad, precio y hoja de ruta
| Hito | Fecha | Detalle |
|---|---|---|
| Early Access | Q3 2025 | Universidades GTC Fellows |
| Preventa pública | GTC Europa 2025 (nov) | Bundle Spark + Omniverse Enterprise 1 a |
| Envíos volumen | Q1 2026 | Servicios Spark Pair listos |
| Spark v2 (GB11) | 2027 | Rumor: HBM3E on‑package, 2 TB/s |